SVM
Towards Data Science: SVM Towards Data Science: SVM an overview
- Dividing line between two classes
- Optimal hyperplane for a space
- Margin maximising hyperplane
- Can be used for
- Classification
- SVC
- Regression
- SVR
- Classification
- Alternative to Eigenmodels for supervised classification
- For smaller datasets
- Hard to scale on larger sets
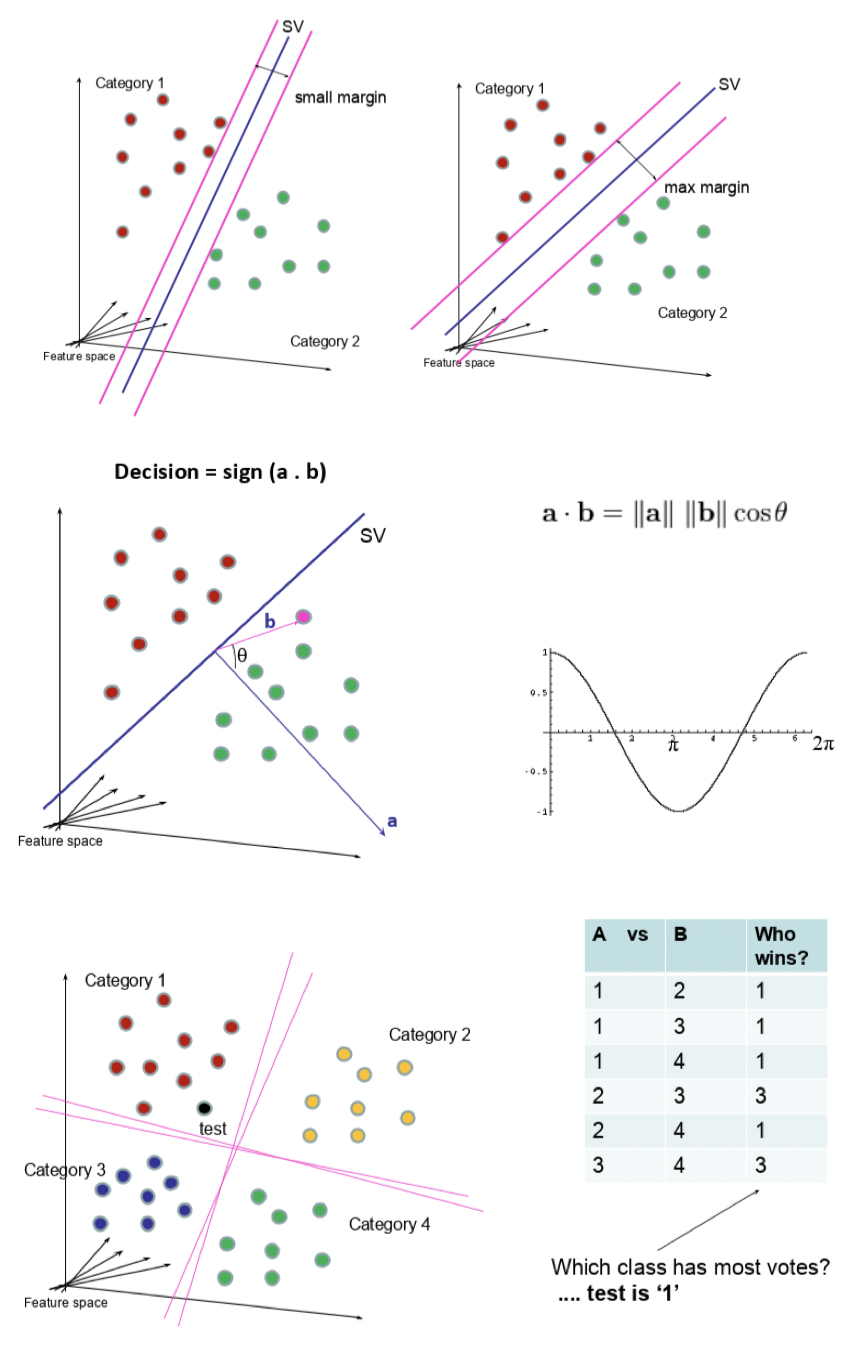
Support vector points
- Closest points to the hyperplane
- Lines to hyperplane are support vectors
Maximise margin between classes
Take dot product of test point with vector perpendicular to support vector
Sign determines class
Pros
- Linear or non-linear discrimination
- Effective in higher dimensions
- Effective when number of features higher than training examples
- Best for when classes are separable
- Outliers have less impact
Cons
- Long time for larger datasets
- Doesn’t do well when overlapping
- Selecting appropriate kernel
Parameters
- C
- How smooth the decision boundary is
- Larger C makes more curvy
- Gamma
- Controls area of influence for data points
- High gamma reduces influence of faraway points
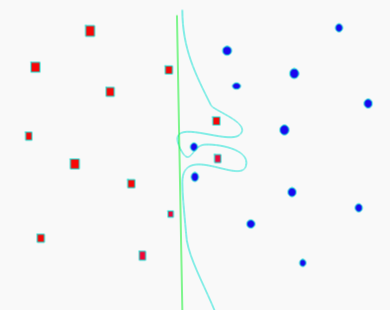
Hyperplane
- -dimensional space
- If satisfies equation
- On plane
- Maximal margin hyperplane
- Perpendicular distance from each observation to given plane
- Best plane has highest distance
- If support vector points shift
- Plane shifts
- Hyperplane only depends on the support vectors
- Rest don’t matter
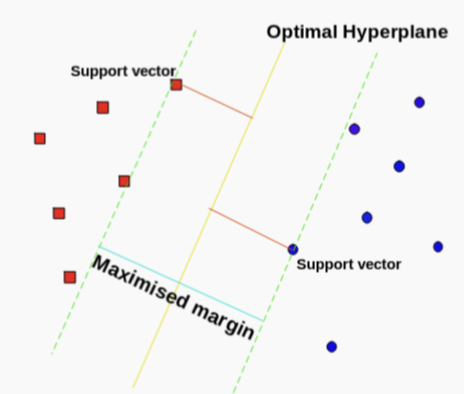
Linearly Separable
- Not linearly separable
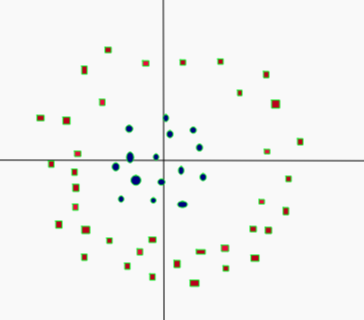
- Add another dimension
- Square of the distance of the point from the origin
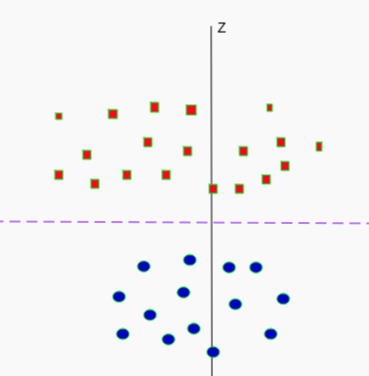
- Now separable
- Let
- is a constant
- Project linear separator back to 2D
- Get circle
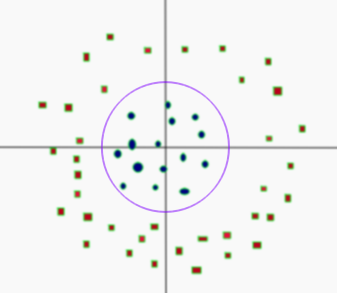
- Get circle