Activation Functions
- Limits output values
- Squashing function
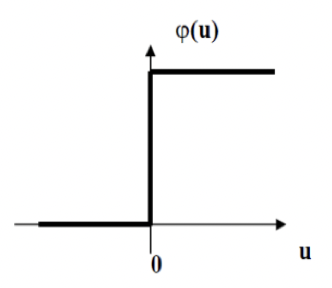
Threshold
- For binary functions
- Not differentiable
- Sharp rise
- Heaviside function
- Unipolar
- 0 <-> +1
- Bipolar
- -1 <-> +1
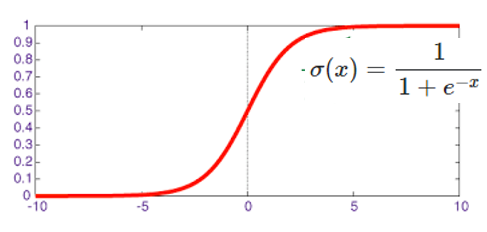
Sigmoid
- Logistic function
- Normalises
- Introduces non-linearity
- Alternative is
- -1 <-> +1
- Easy to take derivative
Derivative
- Nice derivative
- Max value of occurs when
- Min value of 0 when or
- Initial weights chosen so not saturated at 0 or 1
If Where and are differential functions
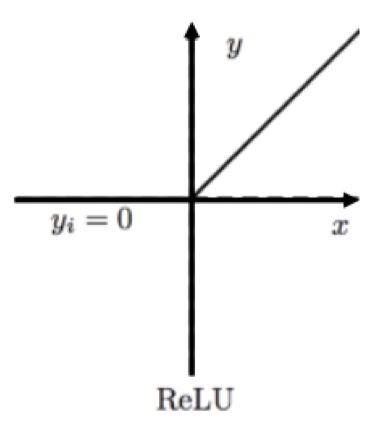
ReLu
Rectilinear
- For deep networks
- CNNs
- Breaks associativity of successive convolutions
- Critical for learning complex functions
- Sometimes small scalar for negative
- Leaky ReLu
- Breaks associativity of successive convolutions
SoftMax
- Output is per-class vector of likelihoods #ai/classification
- Should be normalised into probability vector