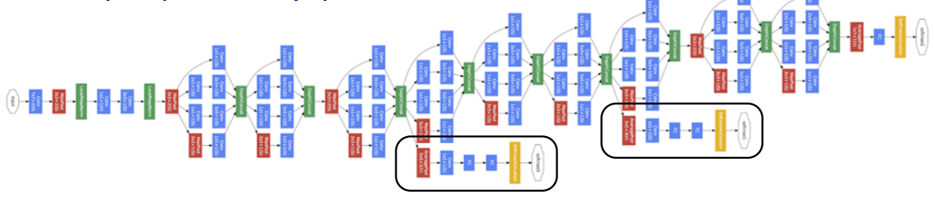
Examples
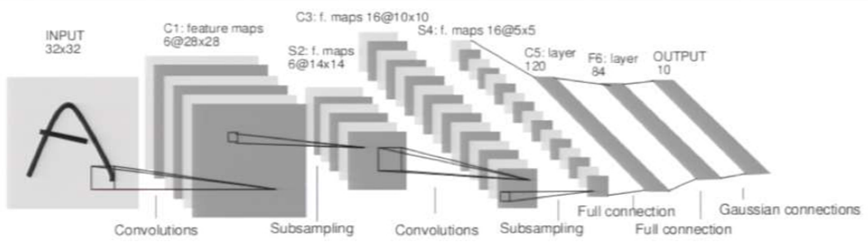
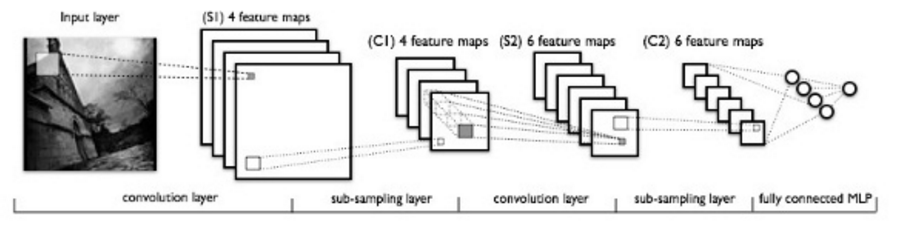
LeNet
- 1990’s
- 1989
- 1998
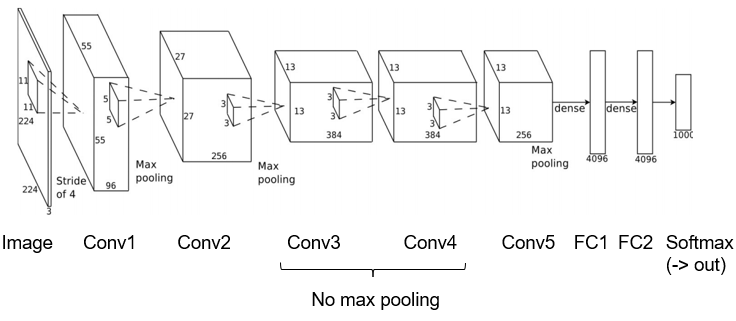
AlexNet
2012
- ReLu
- Normalisation
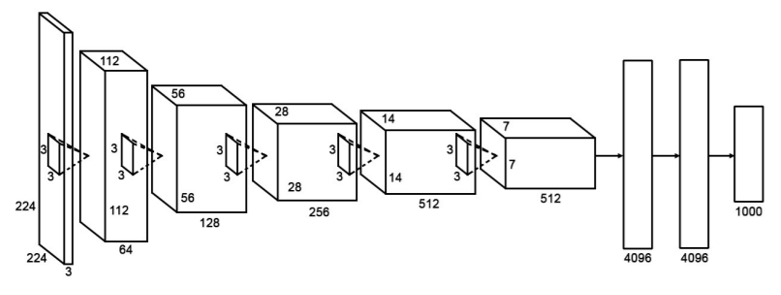
VGG
2015
- 16 layers over AlexNet’s 8
- Looking at vanishing gradient problem
- Xavier
- Similar kernel size throughout
- Gradual filter increase

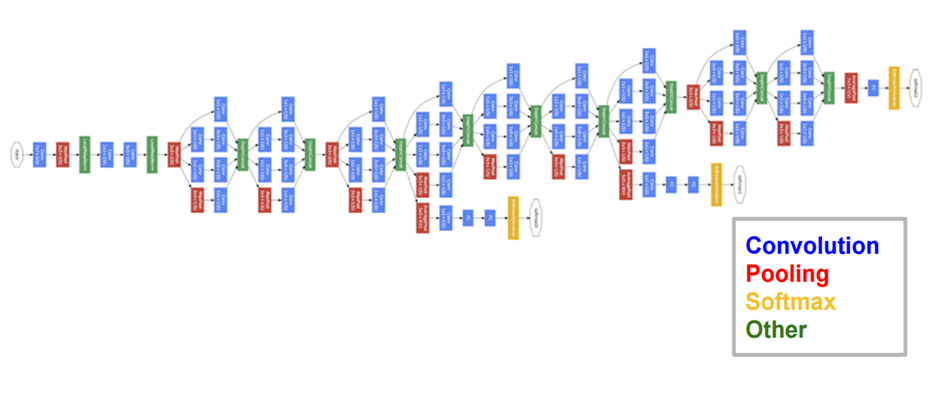
GoogLeNet
2015
- Inception Layers
- Multiple Loss Functions
Inception Layer
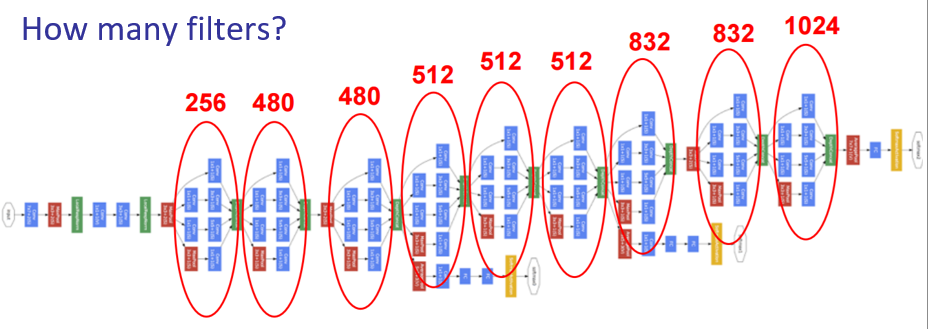
Auxiliary Loss Functions
- Two other SoftMax blocks
- Help train really deep network
- Vanishing gradient problem