Visual Question Answering
- Combine visual with text sequence
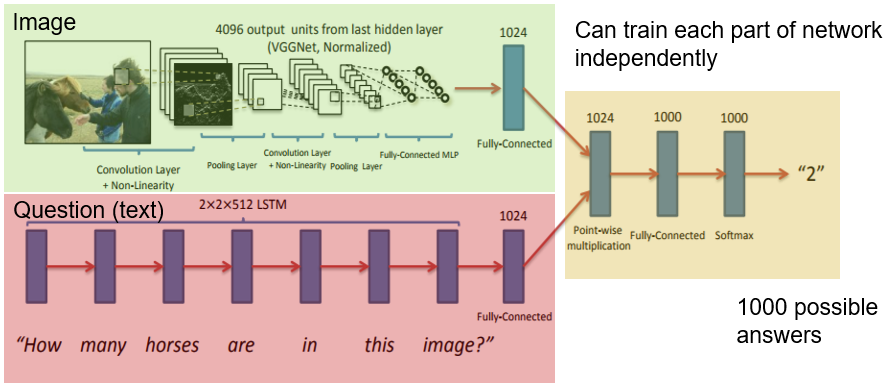
- Word embedding not character
Freeform
- Encode facts with two text streams
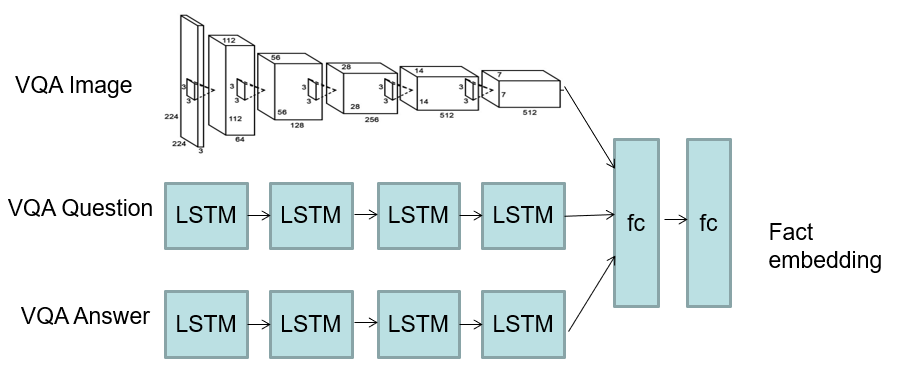
Limitations
- Repetitive answers
- Not much variation
- No creativity
- Wont generalise beyond taught concepts
Visual Question Answering