- To handle overlapping classes
- Linearity condition remains
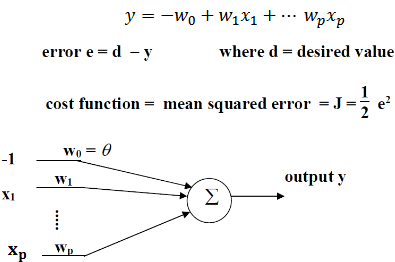
- Linear boundary
- No hard limiter
- Linear neuron
- Cost function changed to error,
- Half doesn’t matter for error
- Disappears when differentiating
- Half doesn’t matter for error
Cost’ w.r.t to weights
Calculate error, define delta
Gradient vector
- Estimate via:
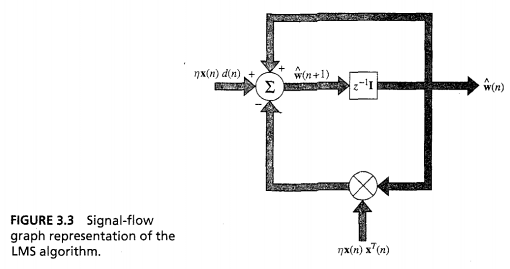
Above is a feedforward loop around weight vector,
- Behaves like low-pass filter
- Pass low frequency components of error signal
- Average time constant of filtering action inversely proportional to learning-rate
- Small value progresses algorithm slowly
- Remembers more
- Inverse of learning rate is measure of memory of LMS algorithm
- Small value progresses algorithm slowly
- Behaves like low-pass filter
because it’s an estimate of the weight vector that would result from steepest descent
- Steepest descent follows well-defined trajectory through weight space for a given learning rate
- LMS traces random trajectory
- Stochastic gradient algorithm
- Requires no knowledge of environmental statistics
Analysis
- Convergence behaviour dependent on statistics of input vector and learning rate
- Another way is that for a given dataset, the learning rate is critical
- Convergence of the mean
- Converges to Wiener solution
- Not helpful
- Convergence in the mean square
- Convergence in the mean square implies convergence in the mean
- Not necessarily converse
Advantages
- Simple
- Model independent
- Robust
- Optimal in accordance with , minimax criterion
- If you do not know what you are up against, plan for the worst and optimise
- Was considered an instantaneous approximation of gradient-descent
Disadvantages
- Slow rate of convergence
- Sensitivity to variation in eigenstructure of input
- Typically requires iterations of 10 x dimensionality of the input space
- Worse with high-d input spaces
- Worse with high-d input spaces
- Use steepest descent
- Partial derivatives

- Can be solved by matrix inversion
- Stochastic
- Random progress
- Will overall improve
Where
Independence Theory

