Transformers
- Self-attention
- Weighting significance of parts of the input
- Including recursive output
- Weighting significance of parts of the input
- Similar to RNNs
- No recurrent structure
Examples
- BERT
- Bidirectional Encoder Representations from Transformers
- Original GPT
transformers-explained-visually-part-1-overview-of-functionality
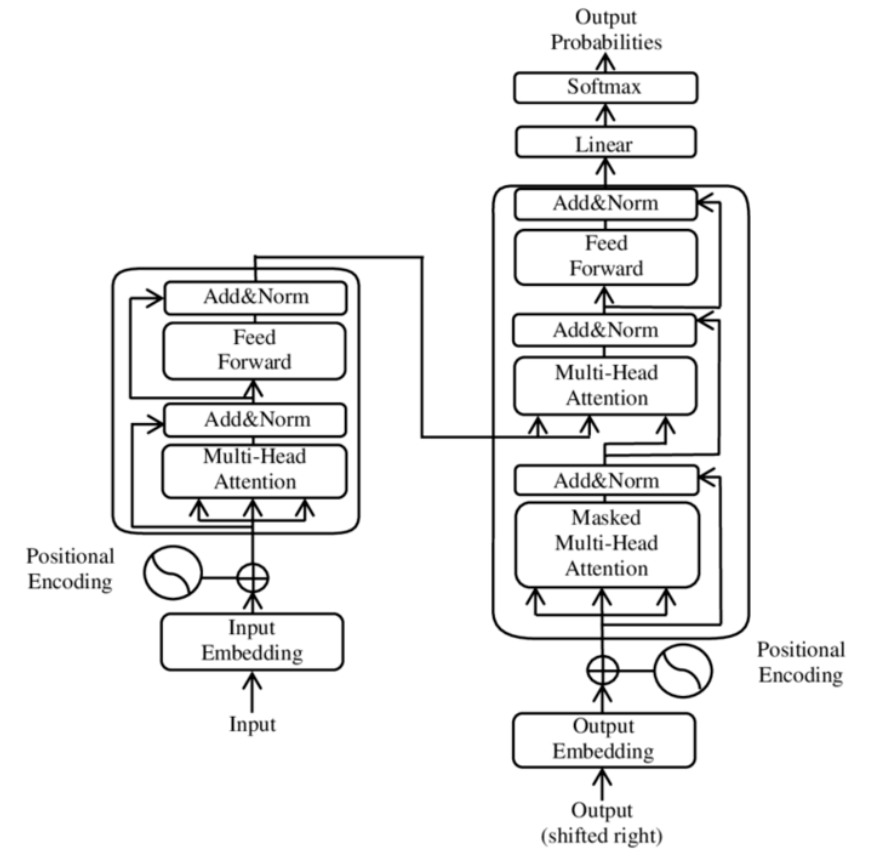
Architecture
Input
- Byte-pair encoding tokeniser
- Mapped via word embedding into vector
- Positional information added
Encoder/Decoder
- Similar to seq2seq models
- Create internal representation
- Encoder layers
- Create encodings that contain information about which parts of input are relevant to each other
- Subsequent encoder layers receive previous encoding layers output
- Decoder layers
- Takes encodings and does opposite
- Uses incorporated textual information to produce output
- Has attention to draw information from output of previous decoders before drawing from encoders
- Both use Attention
- Both use dense layers for additional processing of outputs
- Contain residual connections & layer norm steps