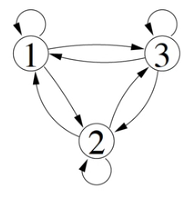
Markov Chains
Hidden Markov Models - JWMI Github Rabiner - A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition
- Stochastic sequences of discrete states
- Transitions have probabilities
- Desired output not always produced the same
- Same pronunciation
1st Order
- Depends only on previous state
- Markov assumption
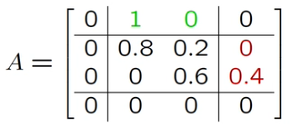
- Described by state-transition probabilities
- State transition
- For states
- by matrix of state transition probabilities
Weather
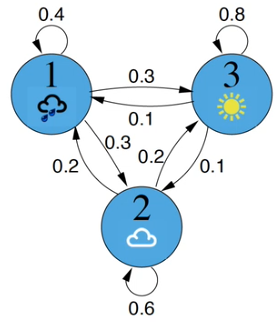
rain, cloud, sun across columns and down rows
Start/End
- Null states
- Entry/exit states
- Don’t generate observations
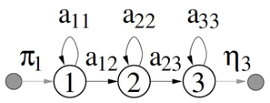
- Sub because probability of kicking off into that state
- Sub because probability of finishing from that state
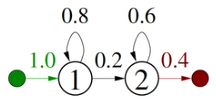
State Duration
- Probability of staying in state decays exponentially
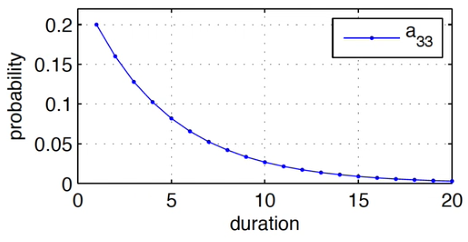
- Given,
- repeatedly
- Stay in state